How Large Language Models Work: An Implementation-Level View

Large Language Models are incredibly complex – and it takes examining many facets to understand how to best implement them to solve real-world problems. One could look at it from the design perspective (layers, heads of attention, vocabulary size), the training perspective (vast data + calculus), or even through the lens of the inference math (matrix multiplication). However, I’m going to focus on implementation level in this blog, dipping a layer below that into why/how something works, but staying out of the deep math. Perhaps an alternative title could be “The IT guide to an LLM.”
This article will focus on the practical implementation pieces, such as:
- How did we have this sudden technological jump with LLMs in recent years?
- What exactly is an LLM doing, anyway?
- How does an LLM learn?
- What algorithms are LLMs using?
- What are the limitations of the algorithms an LLM uses?
- How is information stored in the LLM?
- What are large language model parameters?
- What are hallucinations and why do they happen?
A Quick Reference to the Math of How LLMs Learn
While I’m going to glaze over the more complicated math in this writing, the math is fascinating. I strongly recommend 3Blue1Brown on Youtube if you want to dive into it. There is a shorter one-hour video that summarizes a much longer series on neural networks. If you enjoy that material, I’d recommend starting the full neural network series. You can find a link to both at the bottom of this blog.
But for the rest of this article, assume I’m going to explain the math in just a few words, and leave you to watch the videos if you feel compelled to better understand it.
So, How Do LLMs Learn?
Let’s start with the punchline: LLMs do nothing more than produce the most probable next token (word) in a string of other words. In fact, they’re basically just natural-language probability algorithms.
Leave behind any ideas of genuine thought, understanding a concept at a holistic level, self-awareness, etc. Those things remain in the realm of science fiction for now.
Let’s start with an easy example in English: The cat sat on the .
Most people’s brains will jump to “mat”, automatically. Interestingly, so does llama3 (meta/facebook’s open-weights model):
jkronlage@tangible:~$ ollama run llama3.1:70b-instruct-q8_0
>>> The cat sat on the ….
…mat!
Why is that? Well, because it saw that in training data – with enough reinforcement that the model will almost always predict that token.
What is a Token Regarding an LLM?
I’ve used the word token a couple times, and I’m going to use it a lot more, so let’s define it. A token is a piece of a word, often 3-4 characters, and is the size of data that a model “thinks” in. This tends to turn into two questions: Why not use entire words, or why not use individual letters? There is, of course, math behind the token size which I’m going to skip over. Suffice to say that a token is sized appropriately to optimize the mathematical equation that’s running behind the scenes. For the remainder of this document, we’ll assume a token = word, even though this is often not the case, because it makes demonstration easier.
So, the statistical prediction of the next token was “mat”, given “the cat sat on the” as a prompt. How did it come to know this was the expected next token?
Everything an LLM does is all about its training.
The high-level answer is “because the training data said that pattern enough times”. The model probably also understands rhyming, so it may have guessed this even if it hadn’t seen it in training data.
The low-level answer is considerably more brute-force.
First, we have to have a general concept of what a parameter is.
What Makes up the Parameters of an LLM?
Most LLMs come in parameter sizes of a few billion, with the largest public models in late 2025 reaching into the low trillions of parameters. When appropriately designed, more parameters are indeed more powerful, at a scaling cost of more GPU, more VRAM, more network throughput, more electricity, and more cooling.
A model’s parameters are a mix of two things:
- Weights
- Vocabulary
The vocabulary is the token database and their initial embedding matrix (more on the embedding matrix below) and is relatively small (usually ~1% of the model size). The weights are the tunable parts of a model and tuning them is how a model learns. I like to think of them as knobs on a stereo receiver that can modify a sound. With careful adjustment of those knobs, you can drastically change the output sound and customize that output to your specific environment. When a model is first initialized, the weights are random numbers – essentially junk data. During the training process, the weights are tuned to create patterns.
Let’s look at a very basic example. I’m going to utilize creative liberties and simplification here to keep things simple for now.
But before we can get into training, there’s a couple concepts you need to have a basic understanding of: Forward Pass (w/ Inference), and Backpropagation.
How Does Forward Pass Work?
Forward Pass is the process a set of data (the Context Window) goes through when the model “works on it,” mathematically. In this process, all the weights in the model are activated, and a series of Attention and multi-layer perceptron (MLP) layers are passed through that “solve” the math problem that was your natural language input, with, when inferencing, outputs a single token. If this sounds confusing, don’t sweat it, all you need to know right now is that during Forward Pass + Inference, a series of tokens are input to the model, and a single token is predicted and output (for the mathematically inclined, this is a big series of linear algebra equations). When you’re chatting with an LLM, this is the primary task you’re doing, over and over again.
How Does Backpropagation Work?
Only when training the model, backpropagation is additionally used. It allows the weights of the model to be adjusted slightly – not firmly set – to influence a behavioral change in the model. This process is primarily calculus, but knowing how the math works isn’t necessary for our discussion. Conceptualize it as the inverse of a Forward Pass, and also allows for the tunable weights to be adjusted.
How Do Forward Pass and Backpropagation Lead to an LLM Learning How to Respond?
The training program sits outside the model itself. Dispelling a common myth, the model does not self-train – that’s done externally. If training from scratch, the training program will be loaded up with likely billions of pieces of example text. Let’s assume that the first one it tries to use is our example of “the cat sat on the mat”.
You can visualize the conversation as something like:
Training Program (to itself): Let’s teach this model “the cat sat on the mat”
The training program will basically load up a series of increasingly larger sets of tokens and see if the model is able to predict what the training program knows is the correct output. This is loading the context window with those first few tokens and then instructing a forward pass + inference from the model.
Training Program: “The” <runs a forward pass + inference on the model>
Model Inferences: “foobar” (or any random gibberish that’s in the vocabulary)
Training Program: Wrong, we wanted “cat”, backpropagate and update weights
Training Program: “The cat” <runs a forward pass + inference on the model>
Model: “door” (again, any gibberish)
Training Program: Wrong, we wanted “sat”, backpropagate and update weights
Training Program: “The cat sat” <predict>
Model: “zebra”
Training Program: Wrong, we wanted “on”, backpropagate and update weights
Training Program: “The cat sat on ” <predict>
Model: <more gibberish>
Training Program: Wrong, we wanted “the”, backpropagate and update weights
Training Program: “The cat sat on the ” <predict>
Model: <more gibberish>
Training Program: Wrong, we wanted “mat”, backpropagate and update weights
Training Program: “The cat sat on the mat” <predict>
Model: <ideally would predict a stop token, but still likely gibberish>
Training Program: Wrong, we wanted a stop token, backpropagate and update weights
This process will inevitably fail at every step because the model hasn’t learned how to speak at all yet. However, on a very tiny scale, we’ve just influenced those billions of parameters slightly towards completing “the cat sat on the” input statements with “mat”.
In fact, we just (for better or for worse) taught it that anything starting with “the cat” probably ends in “sat on that mat” whether we wanted that behavior or not. In fact, let’s look at that – what if we wanted to talk about anything else besides where a cat sits? The training program would have to show it more examples of what a cat is, what it does, how it’s involved in sentences, perhaps that it’s a feline, or typically small, and is a pet.
The process takes an enormous amount of data.
And an enormous amount of compute.
And often, a very long time, even if you have the compute to spare.
Training a model from scratch is usually the realm of a ‘supercomputer’, and not something that can be easily reproduced on more affordable equipment.
Is The LLM Using Rote-Memorization or Real Learning?
While we’re on this topic, another common comment is “but wait! This is just memorization!” When you look at it a topic-at-a-time, it’s easy to draw that conclusion. This is part of the magic, though – it’s actual, real learning, not memorization, because these topics can be intermixed with others, creating what seems like new thought.
Sticking with creative liberties and simplification, imagine that the model had now seen enough phrases to mathematically understand sentence structure (admittedly, a big leap from learning one phrase!) and it later started learning more cat-facts as well. In fact, it’s now also learned the phrase “cats like naps.”
Whereas before saying “the cat” would almost certainly (over a series of inferences) produce “sat on the mat,” it may now respond to “the cat” with “The cat took a nap on the mat.” Learning facts, sentence structure, language patterns, etc, are more like building neural pathways in the human mind than they are like memorization. Think of them as tools the model can call on to generate new series of tokens, rather than only being able to regurgitate the same patterns it saw in training.
Let’s Elaborate on a Few Open Topics
I need to make a footnote on a few topics that are, for those paying attention, probably sticking out. All of these could take a lengthy explanation but as they aren’t necessarily vital to understand inside & out from an implementation perspective, I’m going to cover them at high-level. The 3Blue1Brown Neural Network series absolutely knocks these topics out of the park, so please watch their YouTube videos if wanting to dive deeper:
- Embedding matrices and enrichment. I briefly mentioned embeddings above. The vocabulary has an initial embedding matrix that’s measured in dimensions (you programmer types out there – think multi-dimensional arrays, it’s exactly that). Usually a really, really high dimension – one of my favorite models has over 5,000 dimensions per token. Those embeddings represent the mathematical definition of a token, and they’re enhanced at attention layers. Think of the word “Queen” – it might contain the idea of a monarchy, but if you put the words “Freddie Mercury” next to it, the embedding matrix for Queen would shift away from monarchy and towards the numerical representation of a famous rock band.
- This also brings up the idea of directionality. If you start consider the dimensions in a directional sense, you could imagine the embedding moving around in a three dimensional space – try and imagine it as just three dimensions (As opposed to 5,000) as it’s easier on your imagination, with the direction and location shifting to a new spot in a 3d space as a token is enriched. This becomes important when we look at vector searches in a future blog.
- I’ve used “MLP” in a few spots, most notably the diagrams. MLP stands for multilayer perceptron. There’s one MLP for every attention layer in a transformer model. In a very overly simplistic explanation, they help the model memorize “facts”. A common reference point is “Michael Jordan plays…” – basketball, of course. But there’s nothing in the model that acts as a database for this. Naturally, it’s learned from training data, but the MLP tends to soak up factual data, whereas the attention layer focuses more on word-relationships.
Hopefully you’re picking up on how a model learns, but if you’ve used what we now call “AI” since 2022, I imagine you’re thinking “this is sentence-completion, not chat”. And you’d be absolutely correct.
How Have LLMs Changed Recently?
Early LLMs were just completion engines – you could start a sentence, a story, etc, and let the LLM “finish” it for you (often with mixed results). In 2022, approaches for fine-tuning completion models to follow instructions appeared, reference: https://openai.com/index/instruction-following/. The short version is that the base model is trained on a huge amount of natural language first, then supervised-trained on instruction->response pairs, to give the model a “helpful assistant” feeling. These fine-tuned models are called “instruct” models, which you may see referenced on open-weights models from time-to-time, although the labeling is somewhat dying off, as almost all current-generation LLMs are trained on instruct data by default now.
Understanding How Attention Plays Into the Evolution of LLMs
This next explanation could warrant a 50+ page paper to itself, so I’m going to keep the background data to what’s needed from an implementers’ point of view. If you feel compelled to understand the math/science of the process, I would again point you back to the 3Blue1Brown Neural Network series.
In 2017 I remember using Google Translate on a trip to a remote place, and thinking “well, it’s .. ok?”. Phrases usually were built poorly, words out of order, etc. But it got the job done. Somewhere circa 2020 it got downright amazing. My wife is an elementary school teacher and uses it to communicate with non-English-speaking students and raves about it.
Why is that? In 2017, Google researchers published Attention is all you need. https://arxiv.org/abs/1706.03762, which invented the Transformer model. Attention and the Transformer model are at the heart of all modern LLMs, and it’s exactly what catapulted Google translate forward in that time period – Google (by and large) replaced their RNN (Recurrent Neutral Network) model with a Transformer model, and the world changed.
While we’re all eager to discuss what Attention and Transformers actually do, this topic has a lot of confusing bits to it, so I’m going to take a moment to explain:
- It’s of note that Attention is all you need was addressing the shortcomings of RNNs, so from a novice perspective, Attention is not all you need, it was addressing industry insiders and may be more generally described as “Attention + Feed Forward networks are all you need to replace RNNs”.
- Another common misconception is that this paper invented Attention. It did not, it was showing that “Attention + Legacy Methods” were not necessary; scaling up Attention by itself (the “all you need” part) solved all the problems.
- Attention / Transformer models are massively parallelizable, while RNNs were predominantly sequential. This allowed the AI boom to start, as GPUs were suddenly able to mathematically solve the problems of NLP (Natural Language Processing) in parallel, instead of having to work on a sentence one-token-at-a-time.
So What is a Transformer and What Does Attention Do, Anyway?
I’m going to attempt to explain this in the shortest way I can think of, however, we need to hit one topic first. I’ve mentioned a Context Window a couple times. Without the Context Window, the next steps won’t make sense. A Context Window is simply the text that’s in the LLM’s “I’m thinking about this” buffer at any given point in time. It is a limited size window, though on modern models, this can be quite long (sometimes hundreds of pages of text). So when you’re working with an AI chatbot and you paste in 10 paragraphs of text and ask it to summarize, those 10 pages plus the LLMs response plus any future communication you have in response to it, is the context window. It’s what the LLM is considering at any given point in time.
The Transformer model uses Attention to make sense of the often messy, unstructured thing that is human language. The context window is fed in, in one chunk, into the LLM for processing. Not sequentially – the whole, entire context window.
For comparison, let’s look at our “the cat sat on the mat” example in an RNN (pre-transformer):

You end up with six compute steps, none of which can be done simultaneously – this is sequential processing. Transformers & Attention, on the other hand, work like this:
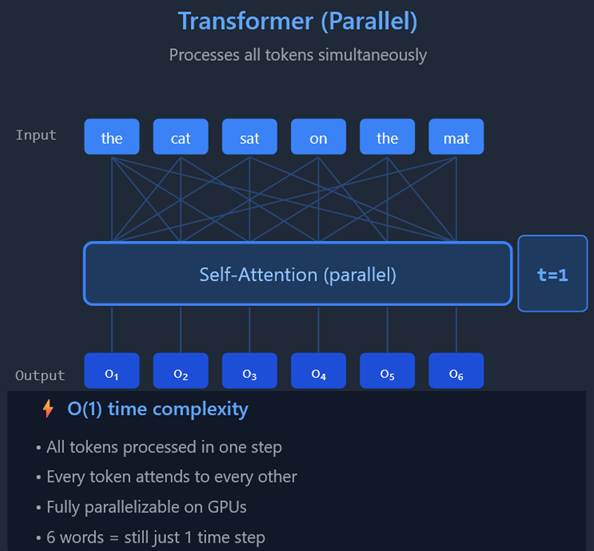
This image represents a lot of topics that need ‘unpacked’, and I will cover them. However, for now, the take-away is that instead of working on a sentence as a sequential set of words, it’s now working on a lot of words at once. GPUs – with their massive core count and efficient memory architecture – were beneficial on RNNs, but they’re mandatory for Transformers where millions of math operations are required to work through even a short document.
What Should I Consider Before Implementing a Transformer Model?
Don’t step away from this thinking Transformers are the end of the story, there’s a lot of engineering that goes into Transformer models as well, and they’re surprisingly complicated. Once again, avoiding any deep math, here’s what you need to know when implementing one.
I’ve expanded our “The cat sat on the mat” example, adding a bit about it enjoying warm milk and being content, as the original example was too simplistic to demonstrate.
Transformers have layers. Generally speaking, more layers = more reasoning power at an increase of power consumption and hardware requirements.
Each layer carries out ‘solving’ part of the context window. This starts with local dependencies (words inside single sentences) in the context window and works towards more distant dependencies over a series of layers.
Transformer Layers in an LLM are Sequential
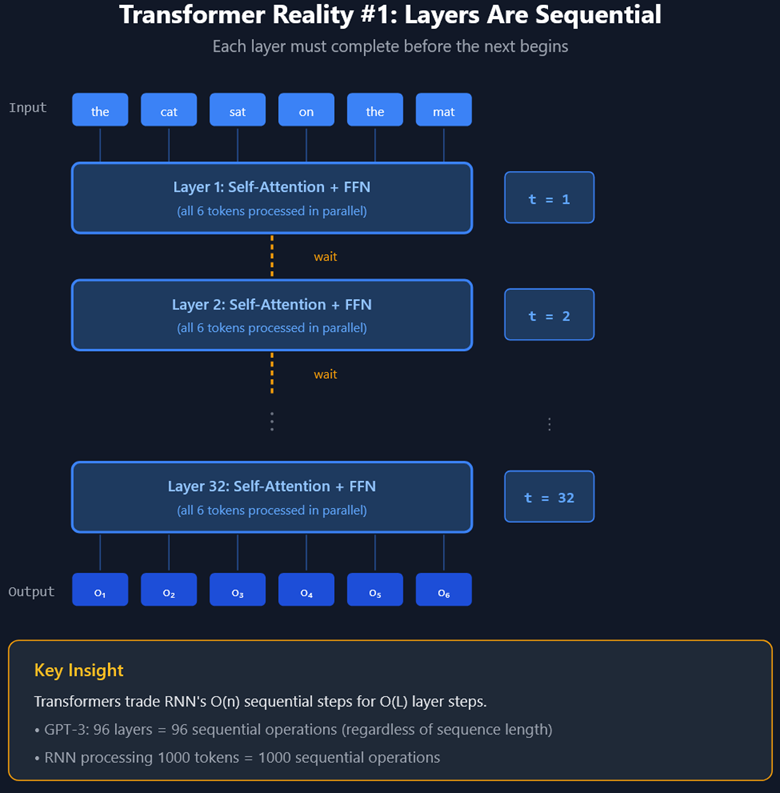
Each layer builds on the one before it, transforming raw pattern-matching into something that looks more like comprehension.
At every layer, each token asks a question (query), advertises what it contains (key), and offers information to share (value) – referred to as QKV. But what gets encoded in these vectors changes as you go deeper.
- Early layers: Queries ask shallow questions — “what’s adjacent to me?” Keys advertise surface features — “I’m a verb,” “I’m a determiner.” Values pass along basic grammatical context. The result is local pattern recognition: “these two words form a phrase.”
- Middle layers: Queries become more sophisticated — “who is my referent?” “what’s my object?” Keys now encode relational roles. A pronoun’s query searches for a noun; a verb’s query searches for its arguments. The result is coherence across sentences.
- Late layers: Queries ask abstract questions — “what’s thematically connected to me?” “what supports my meaning?” Keys encode high-level concepts rather than grammatical roles. Values carry semantic weight. The result is something like comprehension: “this story is about comfort and belonging.”
It’s important to note that the layers are not programmed by humans to perform explicit functions. The increasing complexity of what they solve and how QKV works is emergent behavior and happens naturally as the model is trained!
This is as deep as I’ll take QKV and attention as there are numerous YouTube videos on the topic if you want to learn more.
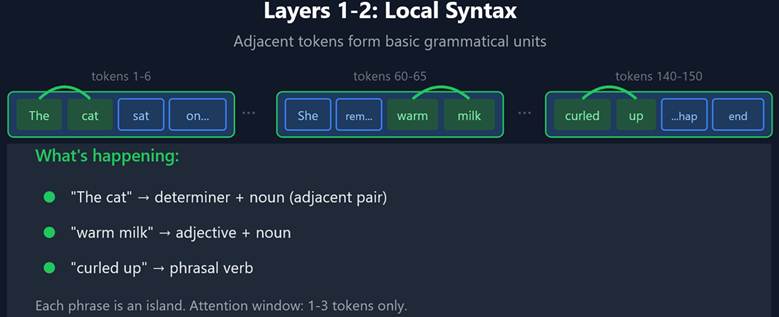
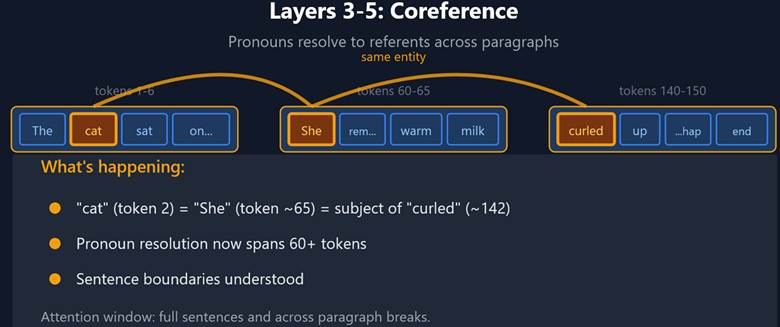
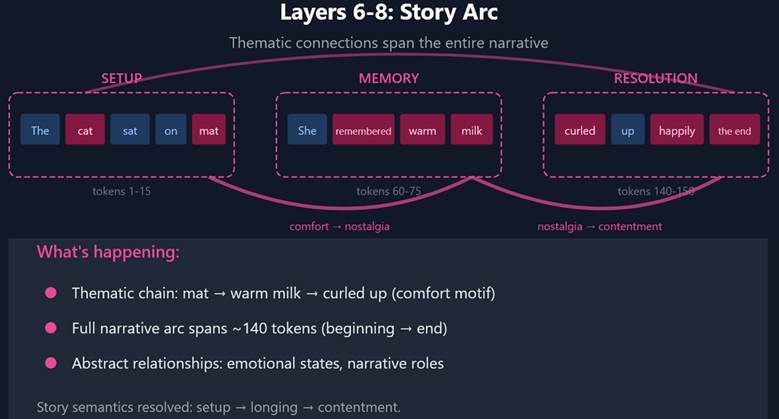
What’s important from an implementation standpoint is:
- Models have layers
- More layers = more complex reasoning, ability to chew threw junk data and get to “what really matters”
- Getting to “what really matters” in a business pipeline is massively important and can differentiate a great AI project from a laughable one.
- More layers = longer compute times (worse performance)
- And indirectly, more layers = more VRAM needed, as larger parameter-count models are needed to allow more training data to enrich the layers.
Each layer is processed serially. So, while Transformers are parallelizable, that’s only inside a single layer, each subsequent layer has to wait on the prior one to complete before moving on.
So unfortunately, we don’t get to cheat out of the time problem. Instead of “t=1” meaning the first word in the sentence would roll into the RLL, t=1 means the first attention layer is being applied, and a lot of in-parallel math is going on.
Consider the Cost of Attention for Transformers in an LLM
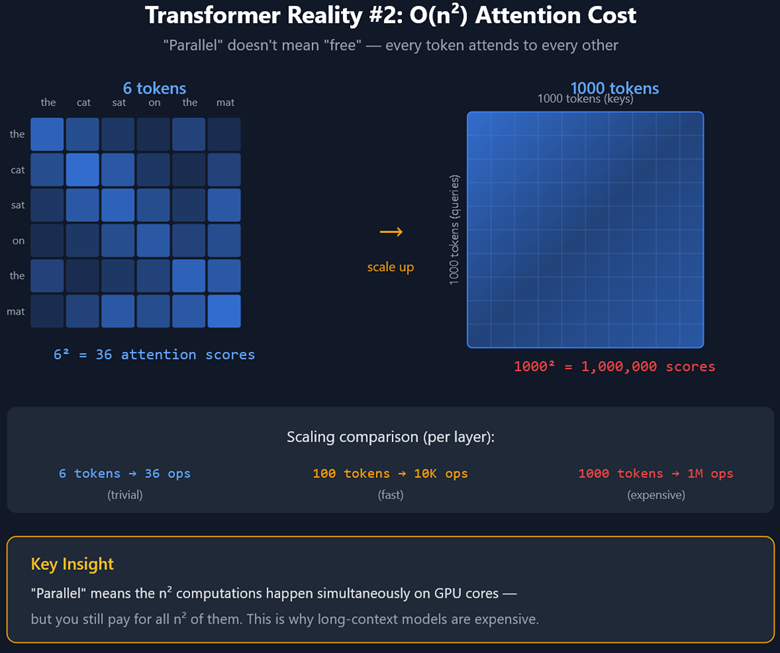
The next item to consider is the compute cost of attention scales quadratically with each token added to the context window. Simply put, a model will process a short context window much faster than it will process a long context window will. When writing pipelined programs, you want to have shorter context windows whenever possible – long ones take time.
Here’s our reworked example using our (hypothetically) lengthened story about a cat, showing the benefits of having sufficient layers to fully process the context window:
A key point I’m trying to make with this is picking the right model for the right job. Contrary to popular belief, you do not have to use one single model for everything. Most of our applications use 3-4 models, ones for very basic tasks (“Is this one-sentence question about personnel?”) to medium topics (“classify this into one of forty groups, as follows…”) through to very complicated ones (“determine which terms in this paragraph can be found in our database, and built a CTE in SQL to locate the correct data, pulling relevant fields for summarization”).
Understanding How to Pick the Right LLM for the Right Job
The right model for the right job: It makes no sense to use a 80-layer model for a yes/no question. On the other hand, using a 28-layer model for a long-context-window prompt with an equally complicated output is sure to result in disaster.
What happens if you don’t have enough layers to interpret a longer context window? Imagine spreading butter over a very large piece of toast. A lot of layers = you’ll have plenty of butter, not enough layers = you’ll end up with butter spread too thinly. More practically, the model will “lose the thread of the conversation”. Using a chatbot as an example, after 30 or 40 back-and-forth prompts, it may seem to start to ‘forget’ what started the conversation, as it can’t rationalize the more recent data with the original data. Or, in the case of a pipelined program, it will become unable to follow all your instructions. You’ll get unpredictable hit-and-miss results where it follows some instructions but not others.
You may be wondering, how exactly do the parameter sizes relate to the number of layers? There’s a correlation. You can think of the number of parameters (mostly weights) as being knobs that can be set during training. Without enough weights, models end up shallow. Too many weights, and they chew up more compute and vram than necessary. With the right amount of weights, the layers can gain their emergent behaviors (ability to code, translate languages, ability to reason over roles, relationships, etc). Generally speaking, more parameters allow for more appropriately-trained layers. There’s a link between parameters/model size and quantity of layers – having 80 layers on a 13b model just doesn’t work.
What Leads to Hallucinations in an LLM?
Let’s cover a favorite topic – hallucinations! First, I would almost argue that hallucinations don’t exist. Yet everyone – even when using public models – seems to have experienced them.
The principle – a model coming up with seemingly ‘hallucinated’ nonsense – is very real. The part I don’t really like is the term, because it implies the model dreamt it up, which is rarely the case with modern models.
I’ve personally encountered three circumstances where hallucinations happen:
- Too little information from the user/program.
- Too much information from the user/program.
- Improper prompting from the user/program.
- Overtrained on specific data (this one may really be a traditional ‘hallucination’).
Let’s break these down:
- Too little information from the user/program. This is more frequently a problem in applications that call an LLM, as it’s easier to make an upstream coding mistake.
Example-
Program inserts variables into LLM: “Customer Name: ACME Inc. Customer Phone Number: 719-555-1111. Customer Summary: Manufacturers premium widgets”.
Program tells LLM: “Identify the customer’s full name from the data provided”
LLM Responds: “John Doe”.
Recall, LLMs are prediction engines. While you can architect something clever to double-check work, this isn’t a native behavior. So the LLM’s action is to run the Attention mechanism on the data and then predict the next token. The most common series of tokens for a name in English is John Doe. There is no considering “Was I actually given a name?”. The instruction is to identify one, and with no other more specific information provided, it predicts the closest thing it knows.
This isn’t really a hallucination in my opinion – it’s bad code, and it happens pretty regularly when you’re mass-feeding data into an LLM.
2. Too much information from the user/program. This could happen with code or in an interactive user session. “Hi, my name is Jeff Kronlage. <400 paragraphs of data goes here>. What was my name?”
LLM Responds: “John Doe”
A really big model will get this right, but a smaller one is going to run out of attention layers, and not be able to correlate <name> == <Jeff Kronlage> with 400 paragraphs of unnecessary junk in the way.
The messy and quick solution is using a bigger model, the much more elegant solution is to figure out how to filter out the hypothetical 400 paragraphs of data before sending the question to the LLM. An interim solution would be to put the name closer to the bottom with the question, as local dependencies are resolved first. Having the necessary data separated from the question by a boatload of noise is not good design.
3. Improper prompting from the user/program.
User or program says to LLM: “Below is a summary of customers, in an unstructured, natural-language format. You are to extract pertinent information from the list, such as customer business name, individual customer names, and phone numbers. Return them in CSV format, such as:
ACME Inc, Kevin Smith, 719-555-1111
Beta Max, Jane Doe, 303-555-1234
<long narrative of customer data is inserted here. One mentions Delta Plus, with a phone number of 800-555-8783, but without a person’s name>”
Model responds:”
…
Delta Plus, Kevin Smith, 800-555-8783
…”
This has probably been the scariest situation I’ve experienced, because the system ‘hallucinated’ what sounds like very plausible data, and especially if you’re doing this with a very long list of data, it’s quite easy to overlook the error.
The solution here is to either reinforce that the absence of a name is an acceptable outcome, such as:
ACME Inc, Kevin Smith, 719-555-1111
Beta Max, , 303-555-1234
Childrens Hospital, Jane Doe, 800-555-7777
Or, simply not use actual names in the examples at all:
<company>, <individual customer name>, <phone>
Both situations have their drawbacks but can be overcome with better training; the training can show what to do when critical data is missing.
4. Improper training. If you’ve reinforced into your model via a supervised fine-tuning that “Kevin Smith” is a common customer name, it will statistically predict that more – usually in the absence of real data. No example required here, but training data needs to reinforce good patterns without accidentally creating bad ones. I’ll write a separate article on training that should provide more insight on this idea.
The takeaway: LLMs are prediction engines, not databases, not traditional programs with long-term memories. They process what’s directly in front of them and don’t carry any state forward. They’re always going to predict whatever feels the most natural, even if it’s “wrong”, based on the data provided to them (garbage in / garbage out).
No State? But wait – you may say, accurately – I’ve seen ChatGPT know my name, or my preferences, or what I was working on days ago in another thread. Yes, this is true! However, the LLM isn’t providing that function. What they’re doing is using an orchestrator to pick out key pieces of data about you and they are putting that in a database. That database can be referenced by the LLM later when needed. We’ll cover parallel concepts to this later, when I write about RAG (Retrieval Augmented Generation).
Understanding Prompt Engineering
I do want to hit one more topic inside this particular article, even though it could really use its own, more robust, standalone article: Prompt Engineering, with a brief touch on what a RAG is. There are too many parallels into what I’ve just finished describing to not bring it up.
I’ve already shown remedial prompt engineering above. It’s just a matter of giving the model a series of instructions you want it to follow and then giving it the data below that.
It usually comes in a format like this:
“Hi there LLM,
- Always provide responses bilingual, English and Spanish.
- When returning data lists, please separate the items in commas.
- Always provide a customer phone number.
<More instructions>
N. Respond in a professional manner.
<data from RAG goes here>” – we’ll cover RAG in a moment, just imagine it being a dataset
First, this is a very, very effective form of prototyping, and I tend to use it quite aggressively when I first start working on a problem. You should always start with this if you’re trying to get the model to do something it isn’t doing by default.
However, there are problems, and they’re directly related to what we’ve been talking about.
First, imagine the instruction set is quite large. Even if they’re all well written, I find, for example, a 13b model falls apart at about 30 instructions inside prompt engineering – the attention layers can’t rationalize all the instructions + process the user data at the same time = you end up with unpredictable results.
The easy and messy fix is to just use a bigger model that can take more instructions. However, that comes at a doubly bad performance trade-off, now not only is the model slower because it’s bigger, but you may recall the compute-processing of a context window scales quadratically the more tokens are in it. So you’re taking a huge token prompt, and sticking it into a bigger model, and watching your performance tank.
The much better solution is to go create labeled training data examples of what a large variety of your inputs might be, along with a large variety of your outputs, and in that matter inherently get the model to do what you want without having to put any instructions on the context window.
Referring to the above – how much I love using prompt engineering for prototyping -I’ll periodically stop and create training examples for the model to instead not need the prompting because it simply does that step by default, as an ingrained action. It doesn’t need to be prompted, because it knows what’s expected of it. Then, you can cut those instructions back out of your prompt engineering.
Another problem might be short prompt engineering, long data:
“Please re-summarize this and make it sound like it was written in Middle English; Shakesperean.
<400 pages of data>”
You may bust the context window size before the data finishes, but at best, it’s not going to be thinking ‘Shakespearean’ by the time it hits the last word in the context window. This will likely get a diluted Shakesperean output, or it will just end up using whatever dialect it was most commonly trained in (whatever the model considers normal speech).
What Does Retrieval Augmented Generation Do for an LLM?
What’s this RAG thing I mentioned? Retrieval Augmented Generation uses an orchestrator to look up data from any source – Word documents, PDF, Excel, SQL databases, APIs, etc – the data is looked up (see the future blog) and pasted into the context window for consideration. Match the right model with the right training and with the right number of engineered prompts (But not relying much too much on them) will get great results.
This blog is intended to explain a lot of the building blocks of putting together a pipelined system. Future blogs will cover RAGs, supervised fine-tuning, and other concepts to bring together a more complete picture.
The major conclusions are:
- LLMs are only prediction engines. Any other functionality besides predicting the next token is typically done with an orchestrator / outside software.
- The Transformer model made LLMs massively parallelizable, dramatically increased the size of LLMs, and made parallelized GPU-based compute a requirement of running them.
- More attention/MLP layers = more reasoning power, however, this comes at a compute and speed cost.
- There’s a correlation between model parameters and layers.
- Initial model training is presently a “requires a supercomputer” task, whereas supervised fine tuning is achievable (expanded on in subsequent blog).
- It’s common for a single application to use a variety of models for different tasks. Big models for big tasks, little models for simple tasks.
- Hallucinations are almost always user/programmer error.
- Prompt engineering is a great way to influence token prediction, especially during prototyping, but scales poorly.
- RAGs are a concept of inserting data from an outside source into an LLM for processing (expanded on in a subsequent blog).
3Blue1Brown Video References on Neural Networks
One Hour Summary Video:
Start of Full Neural Network Series: